2023 年每个软件开发者都必须知道的关于 Unicode 统一码的基本知识
The Absolute Minimum Every Software Developer Must Know About Unicode in 2023 (Still No Excuses!)
作者:Nikita (@tonsky)
Twenty years ago, Joel Spolsky wrote:
二十年前,Joel Spolsky 写道1:
There Ain’t No Such Thing As Plain Text.
It does not make sense to have a string without knowing what encoding it uses. You can no longer stick your head in the sand and pretend that “plain” text is ASCII.
没有所谓的纯文本。
不知道编码的字符串是没有意义的。你不能像鸵鸟一样再把头埋在沙子里,假装「纯」文本是 ASCII。
A lot has changed in 20 years. In 2003, the main question was: what encoding is this?
20 年过去了,很多事情都变了。2003 年的时候,主要的问题是:文本用的是什么编码的?
In 2023, it’s no longer a question: with a 98% probability, it’s UTF-8. Finally! We can stick our heads in the sand again!
到了 2023 年,这不再是一个问题:有 98% 的概率是 UTF-8。终于!我们可以再次把头埋在沙子里了!
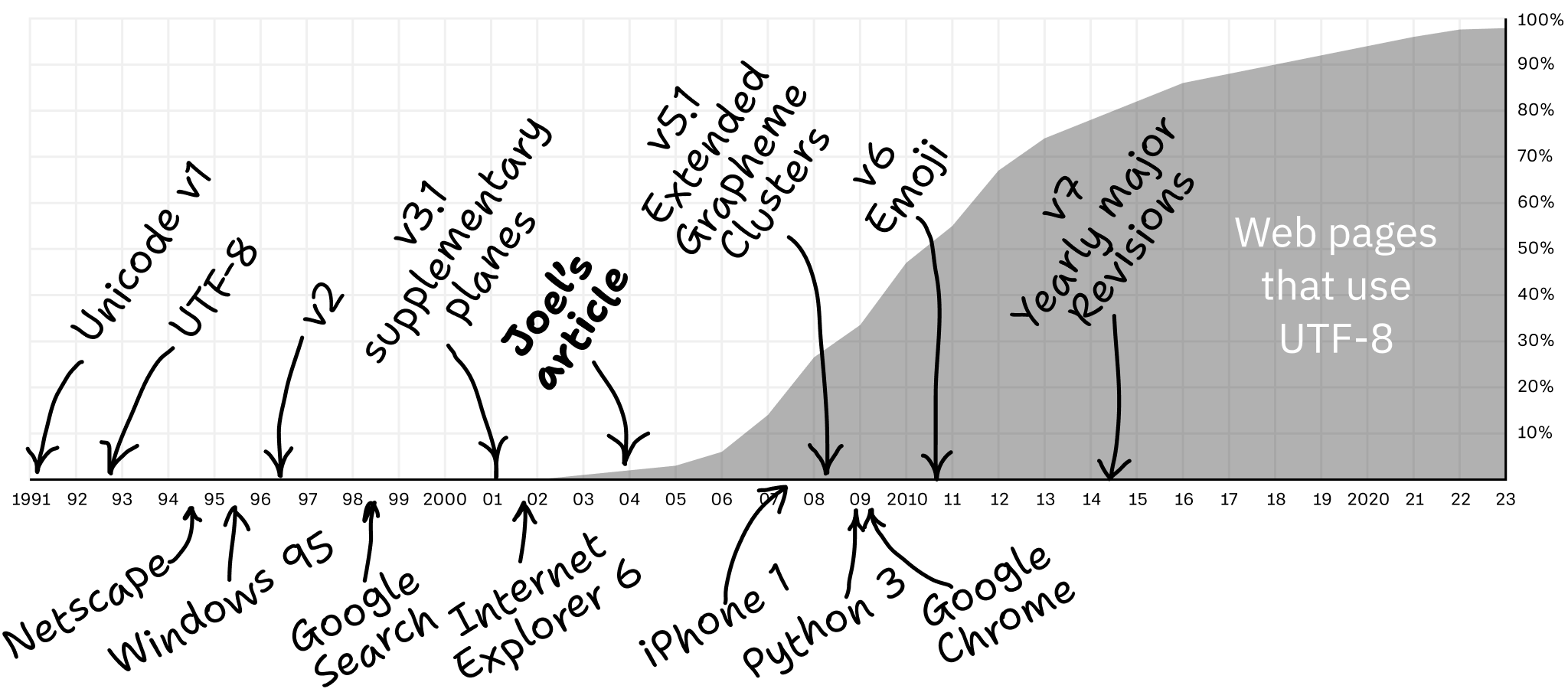
The question now becomes: how do we use UTF-8 correctly? Let’s see!
现在的问题是:我们如何正确地使用 UTF-8?让我们来看看!
What is Unicode?
什么是 Unicode统一码?
Unicode is a standard that aims to unify all human languages, both past and present, and make them work with computers.
Unicode 统一码是一种旨在统一过去和现在的所有人类语言,使其能够在计算机上使用的标准。
In practice, Unicode is a table that assigns unique numbers to different characters.
在实践中,Unicode 统一码是一个将不同字符分配给唯一编号的表格。
For example:
例如:
- The Latin letter
Ais assigned the number65. - 拉丁字母
A被分配了数字65。 - The Arabic Letter Seen
سis1587. - 阿拉伯字母 Seen
س是1587。 - The Katakana Letter Tu
ツis12484 - 片假名字母 Tu
ツ是12484 - The Musical Symbol G Clef
𝄞is119070. - 音乐记号中的高音谱号(G 谱号)
𝄞是119070。 💩is128169.💩是128169。
Unicode refers to these numbers as code points.
Unicode 统一码将这些数字称为码位(code points)。
Since everybody in the world agrees on which numbers correspond to which characters, and we all agree to use Unicode, we can read each other’s texts.
由于世界上的每个人都同意哪些数字对应哪些字符,并且我们都同意使用 Unicode统一码,我们就可以阅读彼此的文本。
Unicode == character ⟷ code point.
Unicode 统一码== 字符 ⟷ 码位。
How big is Unicode?
Unicode 统一码有多大?
Currently, the largest defined code point is 0x10FFFF. That gives us a space of about 1.1 million code points.
目前,已被定义的最大码位是 0x10FFFF。这给了我们大约 110 万个码位的空间。
About 170,000, or 15%, are currently defined. An additional 11% are reserved for private use. The rest, about 800,000 code points, are not allocated at the moment. They could become characters in the future.
目前已定义了大约 17 万个码位,占 15%。另外 11% 用于私有使用。其余的大约 80 万个码位目前没有分配。它们可能在未来变成字符。
Here’s roughly how it looks:
这里是大致的样子:
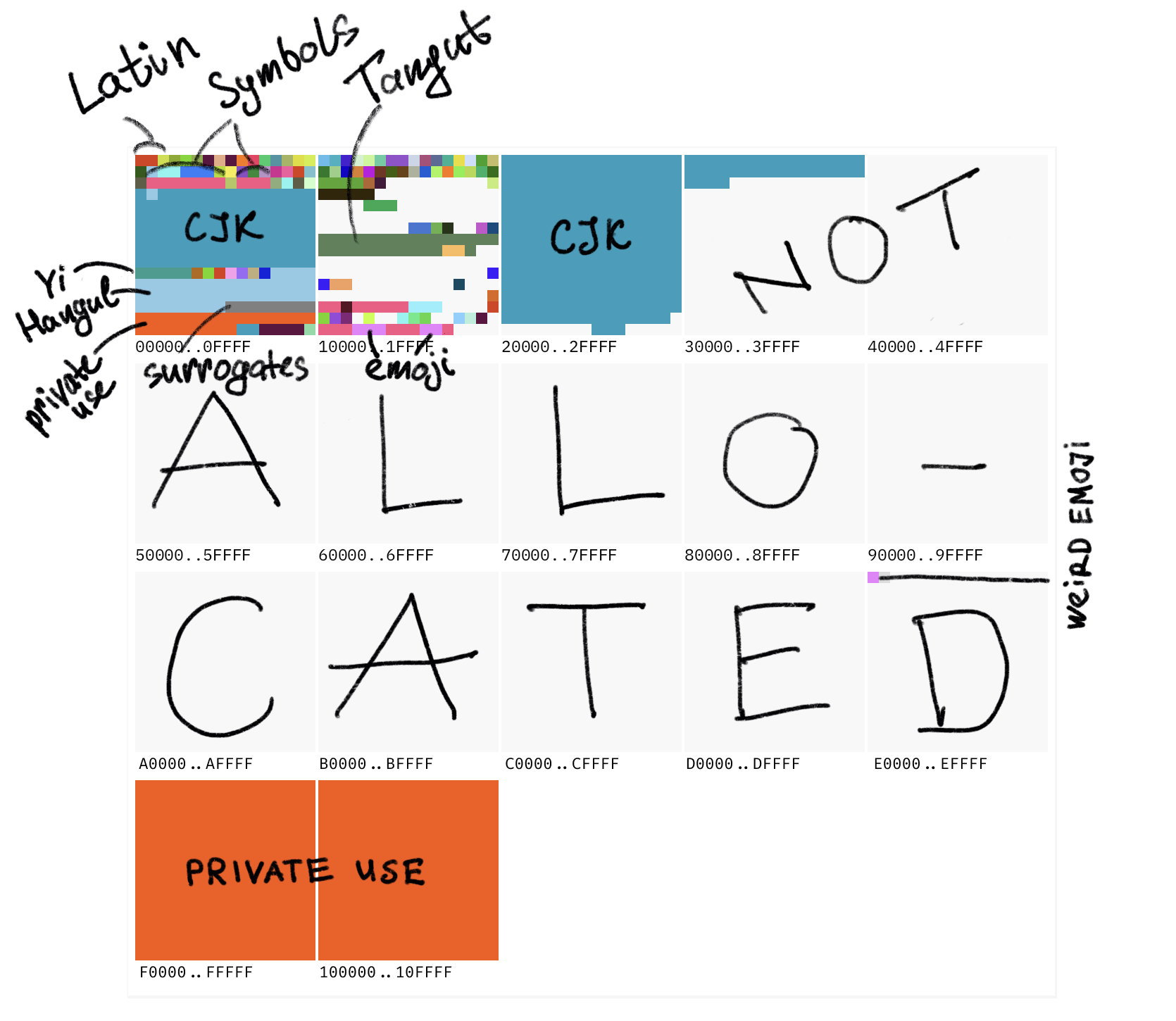
Large square == plane == 65,536 characters. Small one == 256 characters. The entire ASCII is half of a small red square in the top left corner.
大方框 == 平面 == 65,536 个字符。小方框 == 256 个字符。整个 ASCII 是左上角小红色方块的一半。
What’s Private Use?
什么是私用区?
These are code points reserved for app developers and will never be defined by Unicode itself.
这些码位是为应用程序开发人员保留的,Unicode 统一码自己永远不会定义它们。
For example, there’s no place for the Apple logo in Unicode, so Apple puts it at U+F8FF which is within the Private Use block. In any other font, it’ll render as missing glyph , but in fonts that ship with macOS, you’ll see .
例如,Unicode 统一码中没有苹果 logo 的位置,因此 Apple 将其放在私用区块中的 U+F8FF。在任何其他字体中,它都将呈现为缺失的字形 ,但在 macOS 附带的字体中,你就可以看到 。
The Private Use Area is mostly used by icon fonts:
私用区主要由图标字体使用:
What does U+1F4A9 mean?
U+1F4A9 是什么意思?
It’s a convention for how to write code point values. The prefix U+ means, well, Unicode, and 1F4A9 is a code point number in hexadecimal.
这是一种码位值写法的约定。前缀 U+ 表示 Unicode统一码,1F4A9 是十六进制中的码位数字。
Oh, and U+1F4A9 specifically is 💩.
噢,U+1F4A9 具体是 💩。
What’s UTF-8 then?
那 UTF-8 是什么?
UTF-8 is an encoding. Encoding is how we store code points in memory.
UTF-8 是一种编码。编码是我们在内存中存储码位的方式。
The simplest possible encoding for Unicode is UTF-32. It simply stores code points as 32-bit integers. So U+1F4A9 becomes 00 01 F4 A9, taking up four bytes. Any other code point in UTF-32 will also occupy four bytes. Since the highest defined code point is U+10FFFF, any code point is guaranteed to fit.
Unicode 统一码最简单的编码是 UTF-32。它只是将码位存储为 32 位整数。因此,U+1F4A9 变为 00 01 F4 A9,占用四个字节。UTF-32 中的任何其他码位也将占用四个字节。由于最高定义的码位是 U+10FFFF,因此可以保证任何码位都适合。
UTF-16 and UTF-8 are less straightforward, but the ultimate goal is the same: to take a code point and encode it as bytes.
UTF-16 和 UTF-8 不那么直接,但最终目标是相同的:将码位作为字节进行编码。
Encoding is what you’ll actually deal with as a programmer.
作为程序员,编码是你实际处理的内容。
How many bytes are in UTF-8?
UTF-8 中有多少字节?
UTF-8 is a variable-length encoding. A code point might be encoded as a sequence of one to four bytes.
UTF-8 是一种变长编码。码位可能被编码为一个到四个字节的序列。
This is how it works:
这是它工作的方式:
| Code point | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
|---|---|---|---|---|
| 码位 | 第 1 字节 | 第 2 字节 | 第 3 字节 | 第 4 字节 |
U+ | 0xxxxxxx | |||
U+ | 110xxxxx | 10xxxxxx | ||
U+ | 1110xxxx | 10xxxxxx | 10xxxxxx | |
U+ | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
If you combine this with the Unicode table, you’ll see that English is encoded with 1 byte, Cyrillic, Latin European languages, Hebrew and Arabic need 2, and Chinese, Japanese, Korean, other Asian languages, and Emoji need 3 or 4.
将此与 Unicode 统一码表结合起来,就可以看到英语使用 1 个字节进行编码,西里尔语、拉丁语、希伯来语和阿拉伯语需要 2 个字节,中文、日文、韩文、其他亚洲语言和 Emoji 需要 3 个或 4 个字节。
A few important points here:
这里有几个要点:
First, UTF-8 is byte-compatible with ASCII. The code points 0..127, the former ASCII, are encoded with one byte, and it’s the same exact byte. U+0041 (A, Latin Capital Letter A) is just 41, one byte.
第一,UTF-8 与 ASCII 兼容。码位 0..127,即 ASCII,使用一个字节进行编码,而且是完全相同的字节。U+0041 (A,拉丁大写字母 A) 只是 41,一个字节。
Any pure ASCII text is also a valid UTF-8 text, and any UTF-8 text that only uses codepoints 0..127 can be read as ASCII directly.
任何纯 ASCII 文本也是有效的 UTF-8 文本,任何只使用码位 0..127 的 UTF-8 文本都可以直接读取为 ASCII。
Second, UTF-8 is space-efficient for basic Latin. That was one of its main selling points over UTF-16. It might not be fair for texts all over the world, but for technical strings like HTML tags or JSON keys, it makes sense.
第二,UTF-8 对于基本拉丁语来说可以节省空间。这是它比 UTF-16 的主要卖点之一。对于世界各地的文本来说可能不公平,但对于 HTML 标签或 JSON 键等技术字符串来说是有意义的。
On average, UTF-8 tends to be a pretty good deal, even for non-English computers. And for English, there’s no comparison.
平均而言,UTF-8 往往是一个相当不错的选择,即使对于使用非英语的计算机也是如此。而对于英语而言,没有比它更好的选择了。
Third, UTF-8 has error detection and recovery built-in. The first byte’s prefix always looks different from bytes 2-4. This way you can always tell if you are looking at a complete and valid sequence of UTF-8 bytes or if something is missing (for example, you jumped it the middle of the sequence). Then you can correct that by moving forward or backward until you find the beginning of the correct sequence.
第三,UTF-8 自带错误检测和错误恢复的功能。第一个字节的前缀总是与第 2-4 个字节不同,因而你总是可以判断你是否正在查看完整且有效的 UTF-8 字节序列,或者是否缺少某些内容(例如,你跳到了序列的中间)。然后你就可以通过向前或向后移动,直到找到正确序列的开头来纠正它。
And a couple of important consequences:
这带来了一些重要的结论:
- You CAN’T determine the length of the string by counting bytes.
- 你不能通过计数字节来确定字符串的长度。
- You CAN’T randomly jump into the middle of the string and start reading.
- 你不能随机跳到字符串的中间并开始读取。
- You CAN’T get a substring by cutting at arbitrary byte offsets. You might cut off part of the character.
- 你不能通过在任意字节偏移处切割来获取子字符串。你可能会切掉字符的一部分。
Those who do will eventually meet this bad boy: �
试图这样做的人最终会遇到这个坏小子:�
What’s �?
� 是什么?
U+FFFD, the Replacement Character, is simply another code point in the Unicode table. Apps and libraries can use it when they detect Unicode errors.
U+FFFD,替换字符,只是 Unicode 统一码表中的另一个码位。当应用程序和库检测到 Unicode 统一码错误时,它们可以使用它。
If you cut half of the code point off, there’s not much left to do with the other half, except displaying an error. That’s when � is used.
如果你切掉了码位的一半,那就没有什么其他办法,只能显示错误了。这就是使用 � 的时候。
var bytes = "Аналитика".getBytes("UTF-8");
var partial = Arrays.copyOfRange(bytes, 0, 11);
new String(partial, "UTF-8"); // => "Анал�"Wouldn’t UTF-32 be easier for everything?
使用 UTF-32 不会让一切变得更容易吗?
NO.
不会。
UTF-32 is great for operating on code points. Indeed, if every code point is always 4 bytes, then strlen(s) == sizeof(s) / 4, substring(0, 3) == bytes[0, 12], etc.
UTF-32 对于操作码位很棒。确实,如果每个码位总是 4 个字节,那么 strlen(s) == sizeof(s) / 4,substring(0, 3) == bytes[0, 12],等等。
The problem is, you don’t want to operate on code points. A code point is not a unit of writing; one code point is not always a single character. What you should be iterating on is called “extended grapheme clusters”, or graphemes for short.
问题是,你想操作的并非码位。码位不是书写的单位;一个码位不总是一个字符。你应该迭代的是叫做「扩展字位簇(extended grapheme cluster)」的东西,我们在这里简称字位。
A grapheme is a minimally distinctive unit of writing in the context of a particular writing system. ö is one grapheme. é is one too. And 각. Basically, grapheme is what the user thinks of as a single character.
字位(grapheme,或译作字素)2是在特定书写系统的上下文中最小的可区分的书写单位。ö 是一个字位。é、각 也是。基本上,字位是用户认为是单个字符的东西。
The problem is, in Unicode, some graphemes are encoded with multiple code points!
问题是,在 Unicode 统一码中,一些字位使用多个码位进行编码!

For example, é (a single grapheme) is encoded in Unicode as e (U+0065 Latin Small Letter E) + ´ (U+0301 Combining Acute Accent). Two code points!
比如说,é(一个单独的字位)在 Unicode 统一码中被编码为 e(U+0065 拉丁小写字母 E)+ ´(U+0301 连接重音符)。两个码位!
It can also be more than two:
它也可以是两个以上:
☹️isU+2639+U+FE0F☹️是U+2639+U+FE0F👨🏭isU+1F468+U+200D+U+1F3ED👨🏭是U+1F468+U+200D+U+1F3ED🚵🏻♀️isU+1F6B5+U+1F3FB+U+200D+U+2640+U+FE0F🚵🏻♀️是U+1F6B5+U+1F3FB+U+200D+U+2640+U+FE0F- y̖̠͍̘͇͗̏̽̎͞ is
U+0079+U+0316+U+0320+U+034D+U+0318+U+0347+U+0357+U+030F+U+033D+U+030E+U+035E - y̖̠͍̘͇͗̏̽̎͞ 是
U+0079+U+0316+U+0320+U+034D+U+0318+U+0347+U+0357+U+030F+U+033D+U+030E+U+035E
There’s no limit, as far as I know.
据我所知,没有限制。
Remember, we are talking about code points here. Even in the widest encoding, UTF-32, 👨🏭 will still take three 4-byte units to encode. And it still needs to be treated as a single character.
记住,我们在这里谈论的是码位。即使在最宽的编码 UTF-32 中,👨🏭 仍然需要三个 4 字节单元来编码。它仍然需要被视为一个单独的字符。
If the analogy helps, we can think of the Unicode itself (without any encodings) as being variable-length.
如果这个类比有帮助的话,我们可以认为 Unicode 统一码本身(没有任何编码)是变长的。
An Extended Grapheme Cluster is a sequence of one or more Unicode code points that must be treated as a single, unbreakable character.
一个扩展字位簇是一个或多个 Unicode 统一码码位的序列,必须被视为一个单独的、不可分割的字符。
Therefore, we get all the problems we have with variable-length encodings, but now on code point level: you can’t take only a part of the sequence, it always should be selected, copied, edited, or deleted as a whole.
因此,我们会遇到所有变长编码的问题,但现在是在码位级别上:你不能只取序列的一部分——它总是应该作为一个整体被选择、复制、编辑或删除。
Failure to respect grapheme clusters leads to bugs like this:
不尊重字位簇会导致像这样的错误:
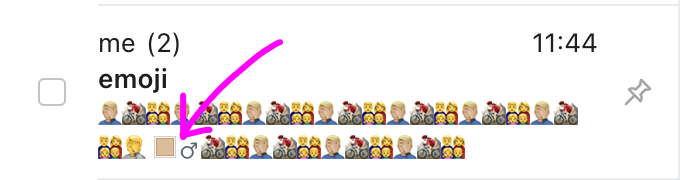
or this:
或者这样:
Using UTF-32 instead of UTF-8 will not make your life any easier in regards to extended grapheme clusters. And extended grapheme clusters is what you should care about.
就扩展字位簇而言,用 UTF-32 代替 UTF-8 不会让你的生活变得更容易。而扩展字位簇才是你应该关心的。
Code points — 🥱. Graphemes — 😍
码位 — 🥱. 字位 — 😍
Is Unicode hard only because of emojis?
Unicode 统一码之所以难,仅仅是因为表情符号吗?
Not really. Extended Grapheme Clusters are also used for alive, actively used languages. For example:
并不。没有消亡的、活跃使用的语言也使用扩展字位簇。例如:
- ö (German) is a single character, but multiple code points (
U+006F U+0308). - ö (德语) 是一个单独的字符,但是多个码位(
U+006F U+0308)。 - ą́ (Lithuanian) is
U+00E1 U+0328. - ą́ (立陶宛语) 是
U+00E1 U+0328。 - 각 (Korean) is
U+1100 U+1161 U+11A8. - 각 (韩语) 是
U+1100 U+1161 U+11A8。
So no, it’s not just about emojis.
所以,不,这不仅仅是关于表情符号。
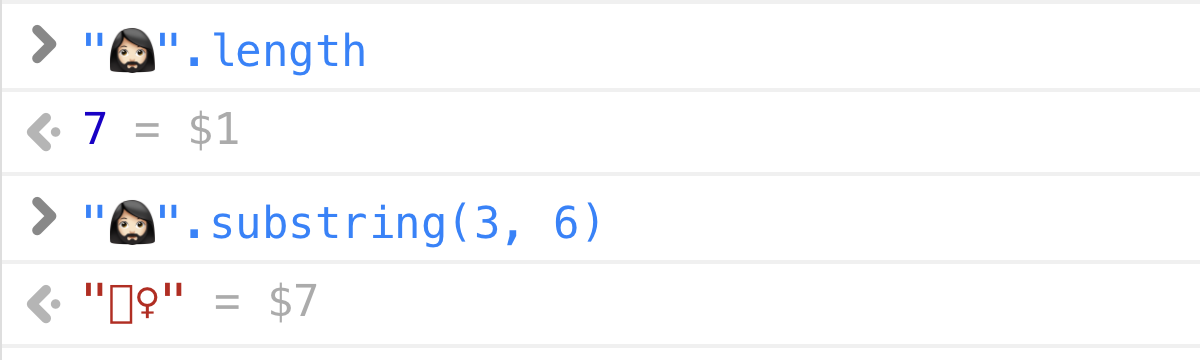
What’s "🤦🏼♂️".length?
"🤦🏼♂️".length 是什么?
The question is inspired by this brilliant article.
这个问题的灵感来自于这篇精彩的文章。
Different programming languages will happily give you different answers.
不同的编程语言很乐意给你不同的答案。
Python 3:
>>> len("🤦🏼♂️")
5JavaScript / Java / C#:
>> "🤦🏼♂️".length
7Rust:
println!("{}", "🤦🏼♂️".len());
// => 17As you can guess, different languages use different internal string representations (UTF-32, UTF-16, UTF-8) and report length in whatever units they store characters in (ints, shorts, bytes).
如你所料,不同的语言使用不同的内部字符串表示(UTF-32、UTF-16、UTF-8),并以它们存储字符的任何单位报告长度(int、short、byte)。
BUT! If you ask any normal person, one that isn’t burdened with computer internals, they’ll give you a straight answer: 1. The length of 🤦🏼♂️ string is 1.
但是!如果你问任何正常的人,一个不被计算机内部所拖累的人,他们会给你一个直接的答案:1。🤦🏼♂️ 字符串的长度是 1。
That’s what extended grapheme clusters are all about: what humans perceive as a single character. And in this case, 🤦🏼♂️ is undoubtedly a single character.
这就是扩展字位簇存在的意义:人们认为是单个字符。在这种情况下,🤦🏼♂️ 无疑是一个单独的字符。
The fact that 🤦🏼♂️ consists of 5 code points (U+1F926 U+1F3FB U+200D U+2642 U+FE0F) is mere implementation detail. It should not be broken apart, it should not be counted as multiple characters, the text cursor should not be positioned inside it, it shouldn’t be partially selected, etc.
🤦🏼♂️ 包含 5 个码位(U+1F926 U+1F3FB U+200D U+2642 U+FE0F)的事实只是实现细节。它不应该被分开,它不应该被计算为多个字符,文本光标不应该被定位在它的内部,它不应该被部分选择,等等。
For all intents and purposes, this is an atomic unit of text. Internally, it could be encoded whatever, but for user-facing API, it should be treated as a whole.
实际上,这是一个文本的原子单位。在内部,它可以被编码为任何东西,但对于面向用户的 API,它应该被视为一个整体。
The only modern language that gets it right is Swift:
唯一没弄错这件事的现代语言是 Swift:
print("🤦🏼♂️".count)
// => 1Basically, there are two layers:
基本上,有两层:
- Internal, computer-oriented. How to copy strings, send them over the network, store on disk, etc. This is where you need encodings like UTF-8. Swift uses UTF-8 internally, but it might as well be UTF-16 or UTF-32. What’s important is that you only use it to copy strings as a whole and never to analyze their content.
- 内部,面向计算机的一层。如何复制字符串、通过网络发送字符串、存储在磁盘上等。这就是你需要 UTF-8 这样的编码的地方。Swift 在内部使用 UTF-8,但也可以是 UTF-16 或 UTF-32。重要的是,你只使用它来整体复制字符串,而不是分析它们的内容。
- External, human-facing API. Character count in UI. Taking first 10 characters to generate preview. Searching in text. Methods like
.countor.substring. Swift gives you a view that pretends the string is a sequence of grapheme clusters. And that view behaves like any human would expect: it gives you 1 for"🤦🏼♂️".count. - 外部,面向人类的 API 一层。UI 中的字数统计。获取前 10 个字符以生成预览。在文本中搜索。像
.count或.substring这样的方法。Swift 给你一个视图,假装字符串是一个字位簇序列。这个视图的行为就像任何人所期望的那样:它为"🤦🏼♂️".count给出 1。
I hope more languages adopt this design soon.
我希望更多的语言尽快采用这种设计。
Question to the reader: what to you think "ẇ͓̞͒͟͡ǫ̠̠̉̏͠͡ͅr̬̺͚̍͛̔͒͢d̠͎̗̳͇͆̋̊͂͐".length should be?
给读者的问题:你认为 "ẇ͓̞͒͟͡ǫ̠̠̉̏͠͡ͅr̬̺͚̍͛̔͒͢d̠͎̗̳͇͆̋̊͂͐".length 应该是什么?
How do I detect extended grapheme clusters then?
如何检测扩展字位簇?
Unfortunately, most languages choose the easy way out and let you iterate through strings with 1-2-4-byte chunks, but not with grapheme clusters.
不幸的是,大多数语言都选择了简单的方法,让你通过 1-2-4 字节块迭代字符串,而不是通过字位簇。
It makes no sense and has no semantics, but since it’s the default, programmers don’t think twice, and we see corrupted strings as the result:
这没有意义,也不合语义,但由于它是缺省值,程序员不会再考虑,我们看到的结果是损坏的字符串:
“I know, I’ll use a library to do strlen()!” — nobody, ever.
「我知道,我会使用一个库来做 strlen()!」——从来没有人这样想。
But that’s exactly what you should be doing! Use a proper Unicode library! Yes, for basic stuff like strlen or indexOf or substring!
但这正是你应该做的!使用一个合适的 Unicode 统一码库!是的,对于像 strlen 或 indexOf 或 substring 这样的基本功能!
For example:
例如:
- C/C++/Java: use ICU. It’s a library from Unicode itself that encodes all the rules about text segmentation.
- C/C++/Java: 使用 ICU。它是一个来自 Unicode 统一码自身的库,它对文本分割的所有规则进行编码。
- C#: use
TextElementEnumerator, which is kept up to date with Unicode as far as I can tell. - C#: 使用
TextElementEnumerator,据我所知,它与 Unicode 统一码保持最新。 - Swift: just stdlib. Swift does the right thing by default.
- Swift: 标准库就行。Swift 默认就做得很好。
- UPD: Erlang/Elixir seem to be doing the right thing, too.
- UPD:Erlang/Elixir 似乎也做得很好。
- For other languages, there’s probably a library or binding for ICU.
- 对于其他语言,可能有一个 ICU 的库或绑定。
- Roll your own. Unicode publishes rules and tables in a machine-readable format, and all the libraries above are based on them.
- 自己动手。Unicode 统一码发布了机器可读的规则和表格,上面的所有库都是基于它们的。
But whatever you choose, make sure it’s on the recent enough version of Unicode (15.1 at the moment of writing), because the definition of graphemes changes from version to version. For example, Java’s java.text.BreakIterator is a no-go: it’s based on a very old version of Unicode and not updated.
不过无论你选哪个,都要确保它是最近的 Unicode 统一码版本(目前是 15.1),因为字位簇的定义会随着版本的变化而变化。例如,Java 的 java.text.BreakIterator 是不行的:它是基于一个非常旧的 Unicode 统一码版本,而且没有更新。
Use a library
用个库
IMO, the whole situation is a shame. Unicode should be in the stdlib of every language by default. It’s the lingua franca of the internet! It’s not even new: we’ve been living with Unicode for 20 years now.
我觉得,整个情况都令人遗憾。Unicode 统一码应该是每种语言的标准库。这是互联网的通用语言!它甚至不是什么新鲜玩意儿:我们已经与 Unicode 统一码生活了 20 年了。
Wait, rules are changing?
等下,规则一直变化?
Yes! Ain’t it cool?
是的!很酷吧?
(I know, it ain’t)
(我知道,这并不)
Starting roughly in 2014, Unicode has been releasing a major revision of their standard every year. This is where you get your new emojis from — Android and iOS updates in the Fall usually include the newest Unicode standard among other things.
大概从 2014 年开始,Unicode 统一码每年都会发布一次主要修订版。这就是你获得新的 emoji 的地方——Android 和 iOS 的更新通常包括最新的 Unicode 统一码标准。
What’s sad for us is that the rules defining grapheme clusters change every year as well. What is considered a sequence of two or three separate code points today might become a grapheme cluster tomorrow! There’s no way to know! Or prepare!
对我们来说可悲的是定义字位簇的规则也在每年变化。今天被认为是两个或三个单独码位的序列,明天可能就成为字位簇!我们无从得知,没法准备!
Even worse, different versions of your own app might be running on different Unicode standards and report different string lengths!
更糟糕的是,你自己的应用程序的不同版本可能在不同的 Unicode 统一码标准上运行,并给出不同的字符串长度!
But that’s the reality we live in. You don’t really have a choice here. You can’t ignore Unicode or Unicode updates if you want to stay relevant and provide a decent user experience. So, buckle up, embrace, and update.
但这就是我们所生活的现实——你实际上别无选择。如果你想站稳脚跟并提供良好的用户体验,就不能忽略 Unicode 统一码或 Unicode 统一码更新。所以,寄好安全带,拥抱更新。
Update yearly
每年更新
Why is “Å” !== “Å” !== “Å”?
为什么 "Å" !== "Å" !== "Å"?

Copy any of these to your JavaScript console:
请将下面任何一行复制到你的 JavaScript 控制台:
"Å" === "Å";
"Å" === "Å";
"Å" === "Å";What do you get? False? You should get false, and it’s not a mistake.
你得到了什么?False?确实是 false,并且这不是一个错误。
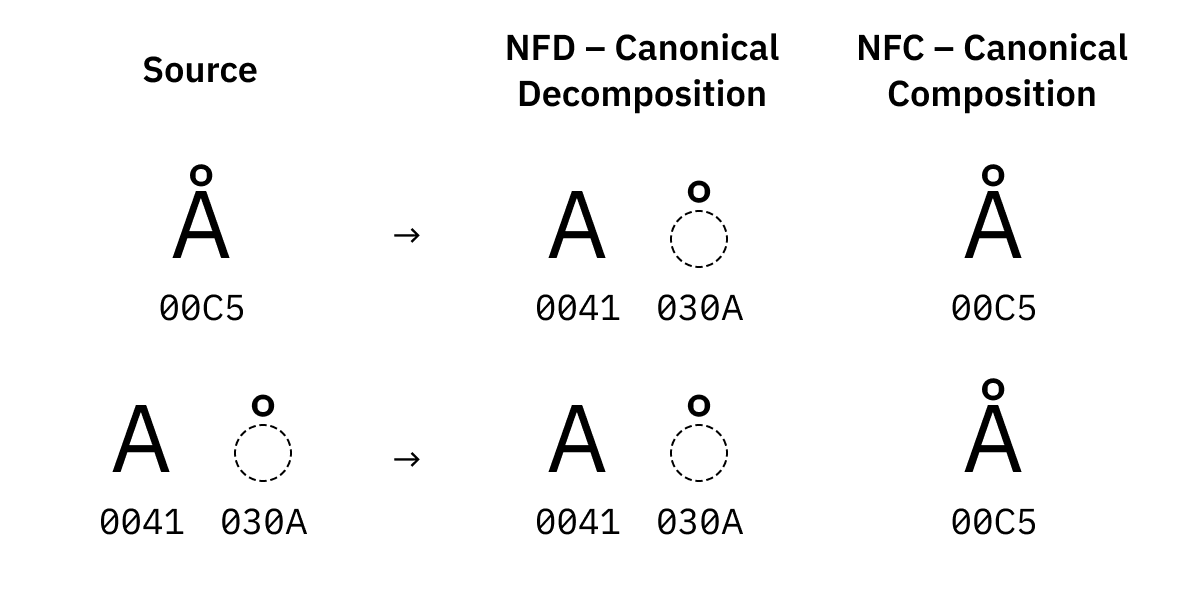
Remember earlier when I said that ö is two code points, U+006F U+0308? Basically, Unicode offers more than one way to write characters like ö or Å. You can:
还记得我之前说过 ö 是两个码位,U+006F U+0308 吗?基本上,Unicode 统一码提供了多种写法,比如 ö 或 Å。你可以:
- Compose
Åfrom normal LatinA+ a combining character, - 从普通拉丁字母
A+ 一个连接字符组合出Å, - OR there’s also a pre-composed code point
U+00C5that does that for you. - 或者还有一个预组合的码位
U+00C5帮你做了这件事。
They will look the same (Å vs Å), they should work the same, and for all intents and purposes, they are considered exactly the same. The only difference is the byte representation.
他们将会看起来一样(Å vs Å),它们应该用起来一样,并且它们实际上在方方面面都被视为完全一样。唯一的区别是字节表示。
That’s why we need normalization. There are four forms:
这就是我们需要归一化的原因。有四种形式:
NFD tries to explode everything to the smallest possible pieces, and also sorts pieces in a canonical order if there is more than one.
NFD 尝试将所有东西都分解为最小的可能部分,并且如果有多个部分,则按照规范顺序对部分进行排序。
NFC, on the other hand, tries to combine everything into pre-composed form if one exists.
NFC,另一方面,尝试将所有东西组合成存在的预组合形式。
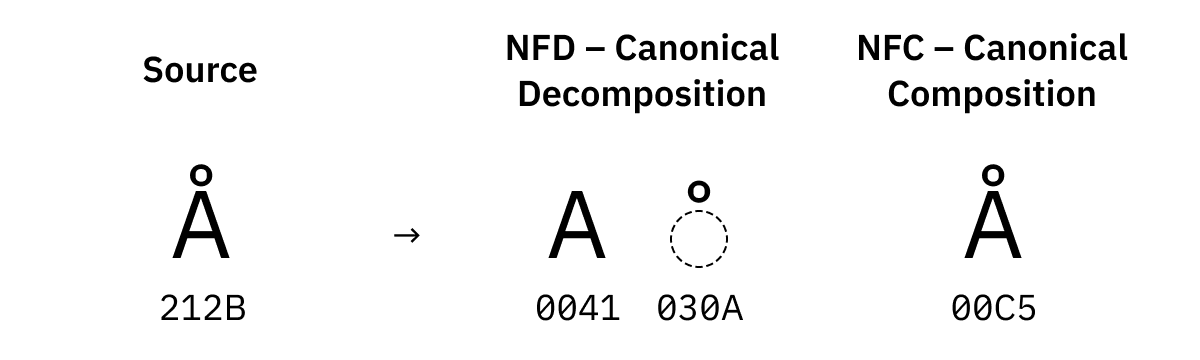
For some characters there are also multiple versions of them in Unicode. For example, there’s U+00C5 Latin Capital Letter A with Ring Above, but there’s also U+212B Angstrom Sign which looks the same.
对于某些字符,它们在 Unicode 统一码中也有多个版本。例如,有 U+00C5 Latin Capital Letter A with Ring Above,但也有 U+212B Angstrom Sign,它看起来是一样的。
These are also replaced during normalization:
这些也在归一化过程中被替换掉了:
NFD and NFC are called “canonical normalization”. Another two forms are “compatibility normalization”:
NFD 和 NFC 被称为「规范归一化」。另外两种形式是「兼容归一化」:
NFKD tries to explode everything and replaces visual variants with default ones.
NFKD 尝试将所有东西分解开来,并用默认的替换视觉变体。
NFKC tries to combine everything while replacing visual variants with default ones.
NFKC 尝试将所有东西组合起来,同时用默认的替换视觉变体。
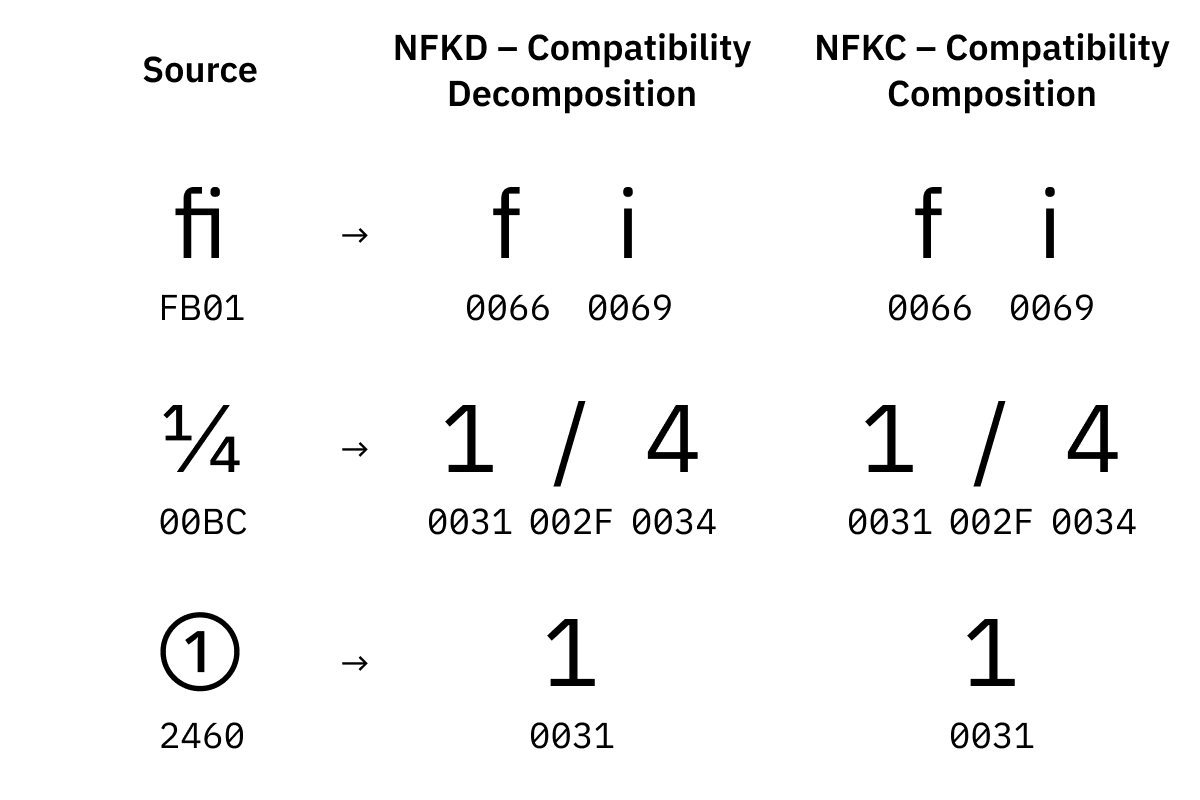
Visual variants are separate Unicode code points that represent the same character but are supposed to render differently. Like, ① or ⁹ or 𝕏. We want to be able to find both "x" and "2" in a string like "𝕏²", don’t we?
视觉变体是表示相同字符的单独的 Unicode 统一码码位,但是应该呈现不同。比如 ① 或 ⁹ 或 𝕏。我们想要在像 "𝕏²" 这样的字符串中找到 "x" 和 "2",不是吗?

Why does the fi ligature even have its own code point? No idea. A lot can happen in a million characters.
为什么连 fi 这个连字都有它自己的码位?不知道。在一百万个字符中,很多事情都可能发生。
Before comparing strings or searching for a substring, normalize!
在比较字符串或搜索子字符串之前,归一化!
Unicode is locale-dependent
Unicode 统一码是基于区域设置的
The Russian name Nikolay is written like this:
俄语名字 Nikolay 的写法如下:
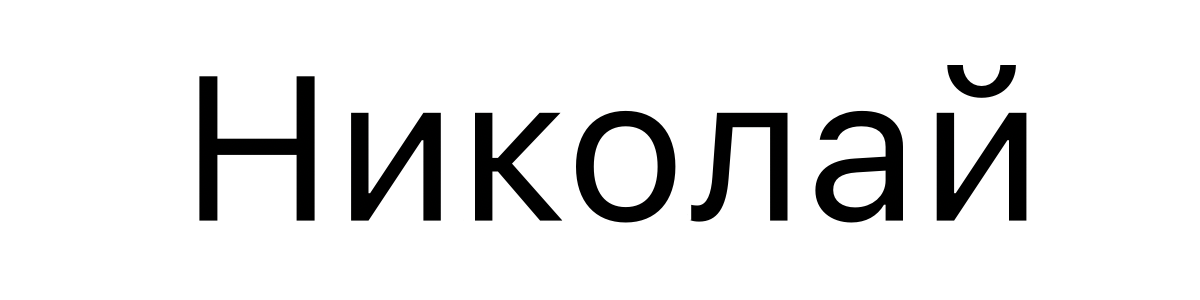
and encoded in Unicode as U+041D 0438 043A 043E 043B 0430 0439.
并且在 Unicode 统一码中编码为 U+041D 0438 043A 043E 043B 0430 0439。
The Bulgarian name Nikolay is written:
保加利亚语名字 Nikolay 的写法如下:
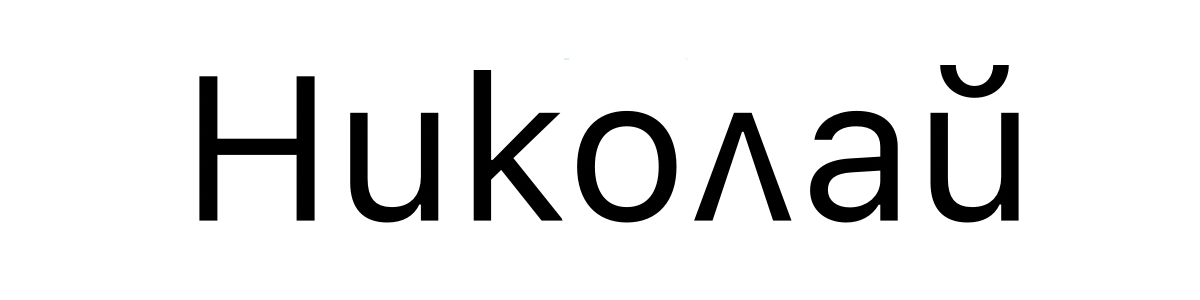
and encoded in Unicode as U+041D 0438 043A 043E 043B 0430 0439. Exactly the same!
并且在 Unicode 统一码中编码为 U+041D 0438 043A 043E 043B 0430 0439。完全一样!
Wait a second! How does the computer know when to render Bulgarian-style glyphs and when to use Russian ones?
等一下!计算机如何知道何时呈现保加利亚式字形,何时使用俄语字形?
Short answer: it doesn’t. Unfortunately, Unicode is not a perfect system, and it has many shortcomings. Among them is assigning the same code point to glyphs that are supposed to look differently, like Cyrillic Lowercase K and Bulgarian Lowercase K (both are U+043A).
简短的回答:它不知道。不幸的是,Unicode 统一码不是一个完美的系统,它有很多缺点。其中之一就是是将相同的码位分配给应该看起来不同的字形,比如西里尔小写字母 K 和保加利亚语小写字母 K(都是 U+043A)。
From what I understand, Asian people get it much worse: many Chinese, Japanese, and Korean logograms that are written very differently get assigned the same code point:
据我所知,亚洲人遭受的打击更大:许多中文、日文和韩文的象形文字被分配了相同的码位:

Unicode motivation is to save code points space (my guess). Information on how to render is supposed to be transferred outside of the string, as locale/language metadata.
Unicode 统一码这么做是出于节省码位空间的动机(我猜的)。渲染信息应该在字符串之外传递,作为区域设置(locale)/语言的元数据。
Unfortunately, it fails the original goal of Unicode:
不幸的是,它未能实现 Unicode 统一码最初的目标:
[…] no escape sequence or control code is required to specify any character in any language.
[…] 不需要转义序列或控制码来指定任何语言中的任何字符。
In practice, dependency on locale brings a lot of problems:
在实际中,对区域设置的依赖带来了很多问题:
- Being metadata, locale often gets lost.
- 作为元数据,区域设置经常丢失。
- People are not limited to a single locale. For example, I can read and write English (USA), English (UK), German, and Russian. Which locale should I set my computer to?
- 人们不限于单一的区域设置。例如,我可以阅读和写作英语(美国)、英语(英国)、德语和俄语。我应该将我的计算机设置为哪个区域?
- It’s hard to mix and match. Like Russian names in Bulgarian text or vice versa. Why not? It’s the internet, people from all cultures hang out here.
- 混起来后再匹配很难。比如保加利亚文中的俄语名字,反之亦然。这种情况不是时有发生吗?这是互联网,来自各种文化的人都在这里冲浪。
- There’s no place to specify the locale. Even making the two screenshots above was non-trivial because in most software, there’s no dropdown or text input to change locale.
- 没有地方指定区域设置。即使是制作上面的两个截图也是比较复杂的,因为在大多数软件中,没有下拉菜单或文本输入来更改区域设置。
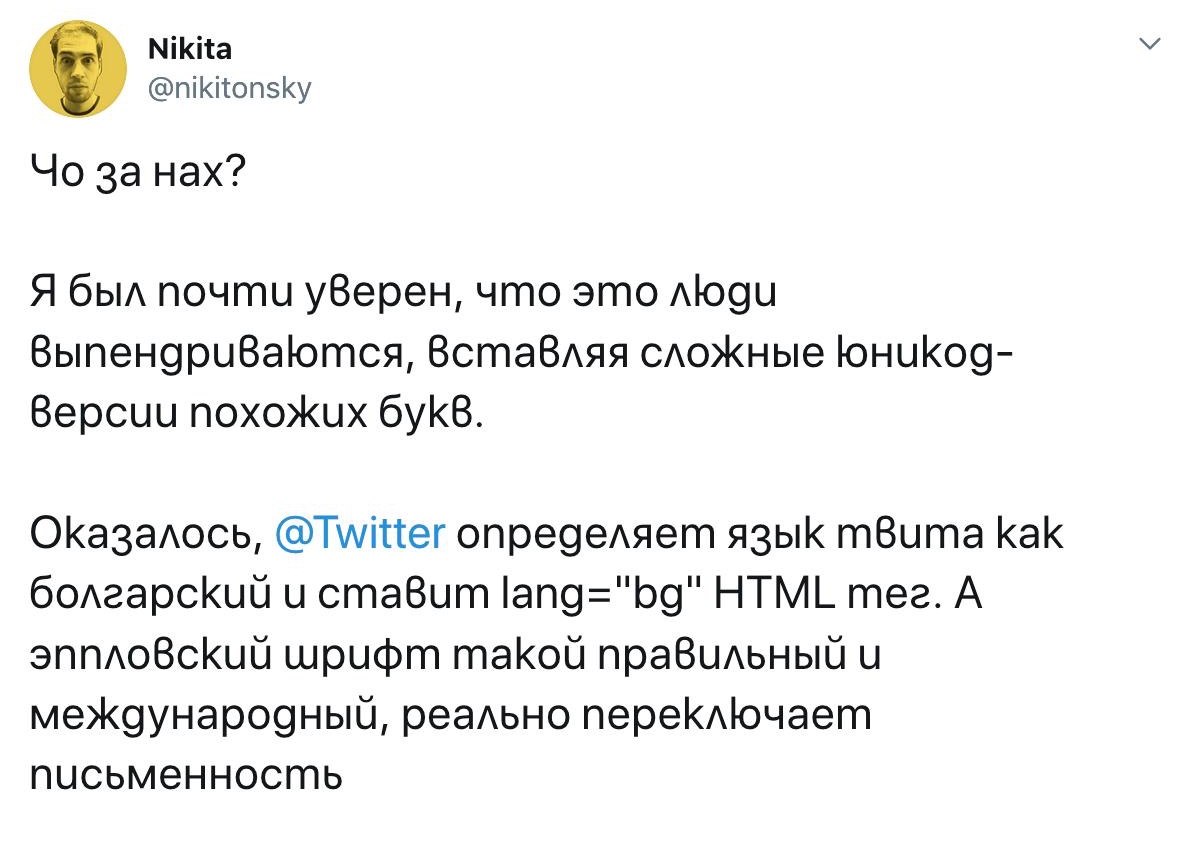
- When needed, it had to be guessed. For example, Twitter tries to guess the locale from the text of the tweet itself (because where else could it get it from?) and sometimes gets it wrong:
- 在需要的时候,我们只能靠猜。例如,Twitter 试图从推文本身的文本中猜测区域设置(因为它还能从哪里得到呢?)时有时会猜错3:
Why does String::toLowerCase() accepts Locale as an argument?
为什么 String::toLowerCase() 的参数中有个区域设置?
Another unfortunate example of locale dependence is the Unicode handling of dotless i in the Turkish language.
Unicode 统一码处理土耳其语中无点 i 的方式是说明其对区域设置依赖的另一个例子。
Unlike English, Turks have two I variants: dotted and dotless. Unicode decided to reuse I and i from ASCII and only add two new code points: İ and ı.
不同于英国人,土耳其人有两种 I 变体:有点的和无点的。Unicode 统一码决定重用 ASCII 中的 I 和 i,并只添加两个新的码位:İ 和 ı。
Unfortunately, that made toLowerCase/toUpperCase behave differently on the same input:
不幸的是,这使得 toLowerCase/toUpperCase 在相同的输入上表现不同:
var en_US = Locale.of("en", "US");
var tr = Locale.of("tr");
"I".toLowerCase(en_US); // => "i"
"I".toLowerCase(tr); // => "ı"
"i".toUpperCase(en_US); // => "I"
"i".toUpperCase(tr); // => "İ"'So no, you can’t convert string to lowercase without knowing what language that string is written in.
所以,不,你不能在不知道字符串是用什么语言编写的情况下将字符串转换为小写。
I live in the US/UK, should I even care?
我住在美国/英国,也应该在意这件事吗?

依然应该。即使是纯英文文本也使用了许多 ASCII 中没有的「排版符号」,比如:
- quotation marks
“”‘’, - 引号
“”‘’, - apostrophe
’, - 撇号
’, - dashes
–—, - 连接号
–—, - different variations of spaces (figure, hair, non-breaking),
- 空格的变体(长空格、短空格、不换行空格),
- bullets
•■☞, - 点
•■☞, - currency symbols other than the
$(kind of tells you who invented computers, doesn’t it?):€¢£, - 除了
$之外的货币符号(这有点告诉你是谁发明了计算机,不是吗?):€¢£, - mathematical signs—plus
+and equals=are part of ASCII, but minus−and multiply×are not¯_(ツ)_/¯ , - 数学符号——加号
+和等号=是 ASCII 的一部分,但减号−和乘号×不是¯_(ツ)_/¯ , - various other signs
©™¶†§. - 各种其他符号
©™¶†§。
Hell, you can’t even spell café, piñata, or naïve without Unicode. So yes, we are all in it together, even Americans.
见鬼,不用 Unicode统一码,你甚至拼写不了 café、piñata
或 naïve。所以是的,我们同舟共济,即使是美国人。
Touché.
法国人:你书的队。4
What are surrogate pairs?
什么是代理对?
That goes back to Unicode v1. The first version of Unicode was supposed to be fixed-width. A 16-bit fixed width, to be exact:
这要追溯到 Unicode 统一码v1。Unicode 统一码的第一个版本应该是固定宽度的。准确地说,是 16 位固定宽度:

They believed 65,536 characters would be enough for all human languages. They were almost right!
他们相信 65,536 个字符足以涵盖所有人类语言。他们几乎是对的!
When they realized they needed more code points, UCS-2 (an original version of UTF-16 without surrogates) was already used in many systems. 16 bit, fixed-width, it only gives you 65,536 characters. What can you do?
当他们意识到他们需要更多的码位时,UCS-2(没有代理对的 UTF-16 的原始版本)已经在许多系统中使用了。16 位,固定宽度,只给你 65,536 个字符。你能做什么呢?
Unicode decided to allocate some of these 65,536 characters to encode higher code points, essentially converting fixed-width UCS-2 into variable-width UTF-16.
Unicode 统一码决定将这 65,536 个字符中的一些分配给编码更高码位的字符,从而将固定宽度的 UCS-2 转换为可变宽度的 UTF-16。
A surrogate pair is two UTF-16 units used to encode a single Unicode code point. For example, D83D DCA9 (two 16-bit units) encodes one code point, U+1F4A9.
代理对(surrogate pair)是用于编码单个 Unicode 统一码码位的两个 UTF-16 单位。例如,D83D DCA9(两个 16 位单位)编码了一个码位,U+1F4A9。
The top 6 bits in surrogate pairs are used for the mask, leaving 2×10 free bits to spare:
代理对中的前 6 位用于掩码,剩下 2×10 个空闲位:
High Surrogate Low Surrogate D800 ++ DC00 1101 10?? ???? ???? ++ 1101 11?? ???? ????
Technically, both halves of the surrogate pair can be seen as Unicode code points, too. In practice, the whole range from U+D800 to U+DFFF is allocated as “for surrogate pairs only”. Code points from there are not even considered valid in any other encodings.
从技术上讲,代理对的两半也可以看作是 Unicode 统一码码位。实际上,从 U+D800 到 U+DFFF 的整个范围都被分配为「仅用于代理对」。从那里开始的码位甚至在任何其他编码中都不被认为是有效的。
Is UTF-16 still alive?
UTF-16 还活着吗?
Yes!
是的!
The promise of a fixed-width encoding that covers all human languages was so compelling that many systems were eager to adopt it. Among them were Microsoft Windows, Objective-C, Java, JavaScript, .NET, Python 2, QT, SMS, and CD-ROM!
一个定长的、涵盖所有人类语言的编码的许诺是如此令人信服,以至于许多系统都迫不及待地采用了它。例如,Microsoft Windows、Objective-C、Java、JavaScript、.NET、Python 2、QT、短信,还有 CD-ROM!
Since then, Python has moved on, CD-ROM has become obsolete, but the rest is stuck with UTF-16 or even UCS-2. So UTF-16 lives there as in-memory representation.
自从那时以来,Python 已经进步了,CD-ROM 已经过时了,但其余的仍然停留在 UTF-16 甚至 UCS-2。因此,UTF-16 作为内存表示而存在。
In practical terms today, UTF-16 has roughly the same usability as UTF-8. It’s also variable-length; counting UTF-16 units is as useless as counting bytes or code points, grapheme clusters are still a pain, etc. The only difference is memory requirements.
在今天的实际情况下,UTF-16 的可用性与 UTF-8 大致相同。它也是变长的;计算 UTF-16 单元与计算字节或码位一样没有用,字位簇仍然很痛苦,等等。唯一的区别是内存需求。
The only downside of UTF-16 is that everything else is UTF-8, so it requires conversion every time a string is read from the network or from disk.
UTF-16 的唯一缺点是其他所有东西都是 UTF-8,因此每次从网络或磁盘读取字符串时都要转换一下。
Also, fun fact: the number of planes Unicode has (17) is defined by how much you can express with surrogate pairs in UTF-16.
还有一个有趣的事实:Unicode 统一码的平面数(17)是由 UTF-16 中代理对可以表达的内容决定的。
Conclusion
结论
To sum it up:
让我们总结一下:
- Unicode has won.
- Unicode 统一码已经赢了。
- UTF-8 is the most popular encoding for data in transfer and at rest.
- UTF-8 是传输和储存数据时使用最广泛的编码。
- UTF-16 is still sometimes used as an in-memory representation.
- UTF-16 仍然有时被用作内存表示。
- The two most important views for strings are bytes (allocate memory/copy/encode/decode) and extended grapheme clusters (all semantic operations).
- 字符串的两个最重要的视图是字节(分配内存/复制/编码/解码)和扩展字位簇(所有语义操作)。
- Using code points for iterating over a string is wrong. They are not the basic unit of writing. One grapheme could consist of multiple code points.
- 以码位为单位来迭代字符串是错误的。它们不是书写的基本单位。一个字位可能由多个码位组成。
- To detect grapheme boundaries, you need Unicode tables.
- 要检测字位的边界,你需要表格。
- Use a Unicode library for everything Unicode, even boring stuff like
strlen,indexOfandsubstring. - 对于所有 Unicode 统一码相关的东西,甚至是像
strlen、indexOf和substring这样的无聊的东西,都要使用 Unicode 统一码库。 - Unicode updates every year, and rules sometimes change.
- Unicode 统一码每年更新一次,规则有时会改变。
- Unicode strings need to be normalized before they can be compared.
- Unicode 统一码字符串在比较之前需要进行归一化。
- Unicode depends on locale for some operations and for rendering.
- Unicode 统一码在某些操作和渲染中依赖于区域设置。
- All this is important even for pure English text.
- 即使是纯英文文本,这些都很重要。
Overall, yes, Unicode is not perfect, but the fact that
总的来说,是的,Unicode 统一码不完美,但
- an encoding exists that covers all possible languages at once,
- 有一个能覆盖所有可能语言的编码、
- the entire world agrees to use it,
- 全世界都同意使用它、
- we can completely forget about encodings and conversions and all that stuff
- 我们可以完全忘记编码和转换之类的东西
is a miracle. Send this to your fellow programmers so they can learn about it, too.
的事实是一个奇迹。把这篇文章发送给你的程序员群友们,让他们也能了解它。
There’s such a thing as plain text, and it’s encoded with UTF-8.
的确有这样一种东西叫做纯文本,
并且它使用 UTF-8 进行编码。
Thanks Lev Walkin and my patrons for reading early drafts of this article.
感谢 Lev Walkin 和我的赞助者们阅读了本文的早期草稿。
YinMo19
液态潮湿圣物
chf007
tcdw
laoshubaby
laoshubaby
ZDY
666
shelken
羊羊羊
猫猫
laoshubaby
laoshubaby
laoshubaby
猫猫
noone
TaylorHere
haneki
est